به لطف کامپیوتر ها جامعه ما دچار تغییرات زیاد و سریع شده است. بخش قابل توجهی از زندگی اجتماعی ما را کامپیوتر و علی الخصوص اینترنت در بر گرفته است. یکی از موضوعات مورد بحث در حال حاضر دنیای کامپیوتر سیستم های توصیه گر می باشد.
سیستم های توصیه گر (Recommender Systems) با اولین ظهورشان در زمینه فیلتر همبستگی حوزه تحقیقاتی مهمی را در اواسط دهه ۱۹۹۰ را فراهم نمودند. دردهه های اخیر دو بخش صنعت و دانشگاه دستاوردهای جدیدی در زمینه سیستم های توصیه گر توسعه داده اند؛ با این وجود علاقه مندی به این بخش هنوز در سطح بالایی است، زیرا حوزه تحقیقاتی غنی بوده و نیاز مبرمی به برنامه های کاربردی فراوانی به منظور کمک به کاربران که با حجم قابل توجه ای از اطلاعات مواجه هستند به منظور شخصی سازی اطلاعات پیشنهادی وجود دارد.
امروزه حجم اطلاعات به شدت در حال افزایش است و بررسی تمام گزینه ها از توانایی یک انسان خارج است. همچنین این امکان که در هر موضوع ما بتوانیم از یک فرد خبره کمک بگیریم، می تواند مشکل هایی داشته باشد. مثلاً ممکن است فرد خبره در دسترس نباشد یا امکان مشاوره در زمان مورد نیاز ما را نداشته باشد. در این نقطه سیستم های توصیه گر (Recommender Systems) ظاهر می شوند و اطلاعات را برای ما متناسب با علایق و خواسته هایمان گزینش می کنند. شما تا به حال برخورد های زیادی با این سیستم ها داشته اید؛ در سایت های خرید مثل دیجی کالا یا سایت های تماشای فیلم مثل آپارات و یوتیوب. به طور مثال شما پس از مدتی گشت و گذار در سایت دیجی کالا و بررسی محصول های موجود، متوجه می شوید که محصول هایی که سایت به شما پیشنهاد می کند در بیشتر مواقع توجه شما را جلب می کند و باب میل شما است. یا به طور مثال هنگامی که یک گوشی تلفن همراه خریداری می کنید، دیجی کالا به شما قاب و صفحه ی محافظ مناسب آن را نیز پیشنهاد می دهد.
سیستم های توصیه گر
حجم فراوان و رو به رشد اطلاعات روی وب و اینترنت، فرایند تصمیم گیری و انتخاب اطلاعات، داده یا کالاهای مورد نیاز را، برای بسیاری از کاربران دشوار و سخت کرده است. این موضوع، خود انگیزه ای شد تا محققین را وادار کند که راه حلی برای رویارویی با این مشکل اساسی عصر جدید که با عنوان سرریز اطلاعات (Information overload) شناخته می شود، پیدا کنند. برای رویارویی با این مسئله تاکنون دو رویکرد مطرح شده است. اولین رویکردی که به کار گرفته شد استفاده از دو مفهوم بازیابی اطلاعات (Information retrieval) و تصفیه کردن اطلاعات بود. عمده محدودیتی که این دو مفهوم در ارائه ی پیشنهادها دارند، این است که برخلاف توصیه گرهای انسانی (مثل دوستان، اعضای خانواده و ...)، این دو روش قادر به تشخیص و تفکیک اقلام با کیفیت و بی کیفیت، در ارائه پیشنهاد برای یک موضوع یا کالا، نبودند و این مسئله باعث شد تا رویکرد دومی به نام سیستم توصیه گر پدید آید. این سیستم های جدید، مشکل سیستم های موجود در رویکرد اولیه را حل کرده اند.
تعاریف متفاوتی برای سیستم های توصیه گر ارائه شده است. از آن جمله، تعریف کلی نگر و خلاصه ی آقای Ting-peng liang در سال ۲۰۰۷ است که سیستم توصیه گر را زیرمجموعه ای از سیستم های پشتیبانی تصمیم (Decision support systems-DSS)، که به آن سیستم های تصمیم یار هم می گویند، می داند و آن ها را سیستم های اطلاعاتی ای تعریف می کند که توانایی تحلیل رفتارهای گذشته و ارائه ی توصیه هایی برای مسائل جاری را دارند. به زبان ساده تر در سیستم های توصیه گر تلاش بر این است تا با حدس زدن شیوه تفکر کاربر (به کمک اطلاعاتی که از نحوه رفتار وی یا کاربران مشابه وی و نظرهای آن ها داریم)، مناسب ترین و نزدیک ترین کالا به سلیقه او را شناسایی کنیم و به او پیشنهاد کنیم. این سیستم ها در حقیقت همان فرایندی که ما در زندگی روزمره خود به کار می بریم و طی آن تلاش می کنیم تا افرادی با سلیقه های نزدیک به خود را پیدا کرده و از آن ها در مورد انتخاب هایمان نظر بخواهیم را شبیه سازی می کنند. توصیه هایی که از سوی سیستم های توصیه گر ارائه می شوند، به طور کلی می توانند دو نتیجه در برداشته باشند:
- کاربر را در گرفتن تصمیمی یاری می کنند (که مثلاً از میان چندین گزینه پیش رو کدام بهتر است و آن را انتخاب کند و ...).
- موجب افزایش آگاهی کاربر، در زمینه مورد علاقه وی می شود (مثلاً ارائه توصیه به کاربر موجب می شود تا وی با اقلام جدیدی که قبلاً آنها را نمی شناخته، آشنا شود).
سیستم های توصیه گر برای هر دو طرف یک تعامل (تجاری یا غیرتجاری)، مفید هستند و مزایایی را فراهم می آورند. برای نمونه، در یک تعامل تجاری، مشتری ها از این جهت که عمل جستجو در میان حجم زیاد اطلاعات برای آن ها تسهیل و تسریع می شود، استفاده از سیستم های توصیه گر را مفید می دانند. فروشندگان هم به کمک این سیستم ها می توانند رضایت مشتریان را بالا برده و فروش خود را نیز افزایش دهند.
سیستم های توصیه گر در کسب و کار
در حال حاضر بسیاری از شرکت های مختلف که سایت های بزرگی دارند برای پیشروی در کارشان از سیستم های توصیه گر استفاده می کنند. با توجه به تفاوت در سلیقه بین افراد مختلف در سنین مختلف بی شک محصولی که یک کاربر انتخاب می کند با کاربر دیگر متفاوت بوده و قطعا عملکرد سیستم های توصیه گر نیز باید متفاوت باشد. سیستم های توصیه گر تاثیر بسزایی درآمد شرکت های مختلف دارند و اگر درست استفاده شوند می توانند سود بسیار بالایی برای شرکت ها به بار آورند به طور مثال شرکت Netflix اعلام کرده است که ۶۰% از DVDهایی که توسط این شرکت به کاربران اجاره داده می شود از طریق سیستم های توصیه گر بوده و این سیستم ها توانستند تاثیر بسزایی در انتخاب مشتریان در انتخاب فیلم ها بگذارند.
مقایسه ی سیستم های توصیه گر و سیستم های پشتیبانی تصمیم
اگر چه شباهت های زیادی بین این دو سیستم وجود دارد اما بین آن ها تفاوت هایی هم هست، که مهم ترین این تفاوت ها، این است که در سیستم های پشتیبانی تصمیم، کاربر نهایی مدیران ارشد یا میانی یک سازمان هستند، در حالی که در سیستم های توصیه گر کاربری سیستم به سطح خاصی محدود نمی شود و سیستم مورد استفاده عام است. اما اگر بحث سطح کاربری و فنی را کنار بگذاریم، هر دوی این سیستم ها کاربر را در گرفتن تصمیم یاری می کنند و هر دو سیستم های اطلاعاتی ای هستند که دارای پایگاه دانش (Knowledge base)، پایگاه داده (Database)، رابط کاربری و ... می باشند.
درست است که سیستم های توصیه گر زیرمجموعه ی سیستم های پشتیبانی تصمیم هستند اما باید بین این دو تمایز قائل شد و درک کرد که سیستم های پشتیبانی تصمیم، به طور معمول باید با مسائل عام که مدیران با آن ها مواجه می شوند رو در رو شود.
اصطلاحات مورد استفاده در فضای بحث توصیه گرها
قبل از اینکه در این موضوع عمیق تر شویم، بهتر است با اطلاحاتی که در این فضا استفاده می شود آشنا شویم و به درک مشترکی از آن ها برسیم.
- کاربر: کاربر به استفاده کننده از سیستم گفته می شود.
- کاربر فعال: به کاربری گفته می شود که توصیه برای او فرستاده می شود. در واقع کاربری که در حال حاضر از سیستم استفاده می کند، کاربر فعال است.
- آیتم: به هر محصول موجود در سیستم یک آیتم گفته می شود. آیتم می تواند یک فیلم، مقاله، موسیقی، وسیله و ... باشد.
- پروفایل: مجموعه ی اطلاعات یک کاربر یا آیتم در پروفایل او نگهداری می شود. برای یک کاربر پروفایل می تواند شامل سن، شغل، موقعیت مکانی باشد. همچنین با در نظر گرفتن سابقه ی کاربر در سرویس ارائه شده علایق و سلیقه ی کاربر نیز می تواند در پروفایل او نگهداری شود و به صورت مداوم به روزرسانی شود. مجموعه اطلاعات آیتم ها هم، همچون برچسب های (Tags) آن، شرح آیتم، امتیازهای داده شده به آیتم و ... نیز در پروفایل آیتم نگهداری می شوند.
تقسیم بندی سیستم های توصیه گر
در کتاب های مختلف تقسیم بندی های مختلفی برای سیستم های توصیه گر وجود دارد. معمول ترین تقسیم بندی سیستم های توصیه گر بصورت زیر است:
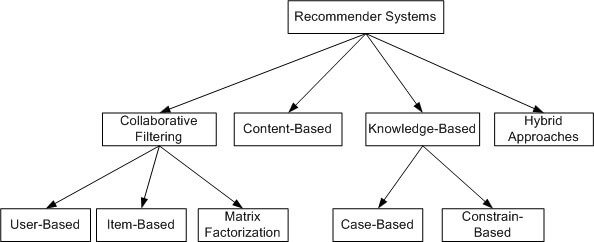
فیلترینگ همکارانه (Collaborative Filtering)
: دراین روش براساس شباهت رفتاری والگوهای عملکردی کاربرانی که شباهت های رفتاری و الگوهای مشابهی با کاربر فعلی در گذشته داشته اند، پیشنهادات را ارائه می کند. شاید تعریف آن کمی پیچیده باشد ولی به طور ساده روش فیلترینگ همکارانه بر این فرض استوار است که کاربرانی که یک سری نظرهای مشابه درباره یک آیتم (منظور از آیتم، فیلم، عکس، موزیک یا هر چیز دیگری است که توصیه می شود) دارند، درباره آیتم های دیگر هم نظرات مشابه دارند. فیلترینگ همکارانه خود شامل سه بخش است که باهم به بررسی آن ها می پردازیم:
- مبتنی بر کاربر (User-based)
< : در این روش افراد هم سلیقه با توجه به امتیازاتی که به آیتم ها داده اند با هم دسته بندی می شوند و چون کاربرانی که سلیقه آن ها شبیه به فرد مورد نظر بود از یک آیتم خوششان آمده بود پس آن آیتم را به فرد مورد نظر نیز پیشنهاد می کنند. - مبتنی بر آیتم (Item-based)
: در این روش وقتی یک کاربر یک آیتم را می بیند، سیستم بصورت خودکار به دنبال آن می گردد که کاربرانی که قبلا این آیتم را دیده اند بعد از آن به دنبال چه آیتم های دیگری را دیده بودند. سپس سیستم آن آیتم ها را به کاربر پیشنهاد می دهد. مثلا در سایت Amazon اگر یک گوشی بخرید بعد از آن، سیستم توصیه گر قاب گوشی و محافظ صفحه نمایشگر و چیزهایی مربوط به گوشی توصیه می کند. - ماتریس عامل بندی(Matrix Factorization)
: درحالی که روش های مبتنی بر کاربر و مبتنی بر آیتم ساده هستند، معمولا روش های ماتریس عامل بندی بیشتر تاثیرگذارند. دلیل آن این است که این روش ها به ما این امکان را می دهند که ویژگی های پنهانی که در بین فعل و انفعالات کاربران و آیتم ها وجود دارد را کشف کنیم. از این روش برای پیش بینی امتیازها در فیلترینگ همکارانه استفاده می کنند. برای مثال دو کاربر ممکن است به آیتم های خاصی امتیاز بالا بدهند و دلیل این کار ممکن است بخاطر بازیگر، کارگردان یا ژانر آن فیلم ها باشد. با تشخیص درست این ویژگی های پنهانی ما می توانیم امتیازها را بر اساس کاربر و آیتم های خاص پیشبینی کنیم.
در سال ۲۰۰۷ شرکت Netflix یک مسابقه برای پژوهش بر روی سیستم های توصیه گر و با استفاده از مجموعه داده ای این شرکت ترتیب داد. در سال ۲۰۰۹ جایزه یک میلیون دلاری به یکی از پژوهشگران رسید. یکی از الگوریتم هایی که آن ها در روش خود استفاده کرده بودند همین روش ماتریس عامل بندی بود و این نشانه قدرت و توانایی این روش است.
فیلترینگ مبتنی بر محتوا (Content-based) :
فیلترینگ مبتنی بر محتوا از اطلاعات متنی و سابقه های کاربر برای تطابق آیتم ها استفاده کرده و گزینه های مناسب را پیشنهاد می دهد. دانش اصلی ای که در این تکنیک استفاده می شود اطلاعات آیتم ها است مثل ژانر، سال تولید و … که براساس این اطلاعات، آیتم هایی که شبیه به هم هستند توصیه می شوند. نمونه عمده این روش در وب سایت Amazon برای پیشنهاد کتاب ها بر اساس کلمات کلیدی کتاب های مشابه که قبلا توسط کاربر خریداری شده استفاده می شود.
اما این دو روش توصیه محدودیت هایی دارند. محدودیت های استفاده از فیلترینگ همکارانه و فیلترینگ مبتنی بر محتوا را می توانید در قالب مثال بعدی ببینید. معمولا ما بصورت مکرر ماشین ، خانه و یا کامپیوتر نمی خریم. در این سناریوها یک سیستم فیلترینگ همکارانه خوب عمل نمی کند چون تعداد امتیازهای موجود بسیار کم است. علاوه بر این، محدوده زمانی نقش مهمی ایفا می کند. برای مثال، امتیازهایی که ۵ سال قبل به یک کامپیوتر داده شده است به طور قطع برای توصیه مبتنی بر محتوا مناسب نیست.
مبتنی بر دانش (Knowledge-based) :
این روش چالش های ذکر شده را حل می کند. سیستم های توصیه گر مبتنی بر دانش، نسل جدیدی از سیستم های توصیه گر هستند که مبتنی بر دانش موجود در رابطه با کاربران و آیتم ها هستند. چنین سیستم هایی، پیشنهادات خود را بر پایه تفسیر و استنباط خود از سلایق و نیاز های کاربر ارائه می دهند و از دیدگاه تئوری نسبت به سایر روش های ذکر شده از دقت و کیفیت بیشتری برخوردار هستند. طبیعی است که برای پیاده سازی چنین سیستم هایی نیاز به یک بستر و ساختار مبتنی بر دانش وجود دارد. در این گونه از سیستم های توصیه گر مواد اولیه مورد استفاده برای تولید لیستی از پیشنهادها، دانش سیستم در مورد مشتری و کالا است. سیستمهای مبتنی بر دانش از متدهای مختلفی که برای تحلیل دانش قابل استفاده هستند بهره میبرند که متدهای رایج در الگوریتمهای ژنتیک، فازی، شبکههای عصبی و … از جمله آنها است. همچنین، در این گونه سیستم ها از درختهای تصمیم، استدلال نمونه محور و … نیز میتوان استفاده کرد. روش مبتنی بر دانش خود به دو روش مبتنی بر محدودیت (Constrain-based) و مبتنی بر مورد (Case-based) تقسیم می شود. هر دو روش از لحاظ فرایند توصیه یکسان هستند یعنی اول یک کاربر باید بطور دقیق درخواست خود را بگوید سپس سیستم تلاش می کند که یک راه حل تشخیص بدهد. سیستم حتی می تواند یک توضیح کوتاهی برای اینکه چرا یک آیتم رو توصیه کرده است بدهد. اما این دو روش از لحاظ تهیه دانش باهم متفاوتند. روش مبتنی بر مورد، آیتم های مشابه را با استفاده از تشابه (similarity measure) توصیه می کند اما روش مبتنی بر محدودیت، با توجه به قانون های توصیه ای که از قبل به طور صریح تعبیه شده فرایند توصیه را انجام می دهد.
روش های ترکیبی (Hybrid approaches) :
این روش ترکیبی از روش های قبلی است که سعی کرده با ترکیب روش ها از مزیت آن روش ها استفاده کند و محدودیت های آن ها را پوشش دهد.
در نتیجه، سیستم های توصیه گر یکی از به روزترین مباحث تحقیقاتی در سطح جهان است. اهمیت بالای استفاده از سیستم های توصیه گر در کسب و کار و بازده بالای آن باعث شده که هر روز مقاله های جدیدی در این زمینه ارائه شوند. به طور قطع تا چند سال آینده این مبحث به عنوان یکی از مهم ترین مباحث پژوهشی باقی خواهد ماند.


.webp)

